
本篇重點
- 搜尋引擎透過建立倒排索引(Inverted Index)來提升查詢效率
- 一般資料庫擅長資料儲存與交易處理,搜尋引擎則專注於資料檢索
- 搜尋引擎的優勢是全文檢索、模糊搜尋與相關性排序
- 適合導入搜尋引擎的場景有哪些
- 搜尋引擎可作為系統架構中的檢索層,降低資料庫查詢壓力
什麼是搜尋引擎
搜尋引擎(Search Engine)是一種專門用於資料檢索的系統,其核心目標是在大量資料中快速找到最符合需求的內容。
常見的搜尋引擎包括
- Elasticsearch:功能強大,生態系豐富,適合海量資料與複雜分析。
- OpenSearch:Elasticsearch 的開源分支(由 AWS 維護),功能高度相似,適合偏好開源架構者。
- Apache Solr:老牌、極其穩定,在企業級內容搜尋上有深厚根基(如大型網站文件檢索)。
- Meilisearch:以「極致效能」與「易用性」為目標,設定簡單,非常適合小型專案或即時搜尋體驗。
這些是「應用軟體」或「中間件(Middleware)」,並非「打開即用」的應用程式,需部署、資料同步後再串接。如果希望找開箱即用產品,可以使用 Algolia 這樣的 SaaS 服務。
搜尋引擎與資料庫的差異
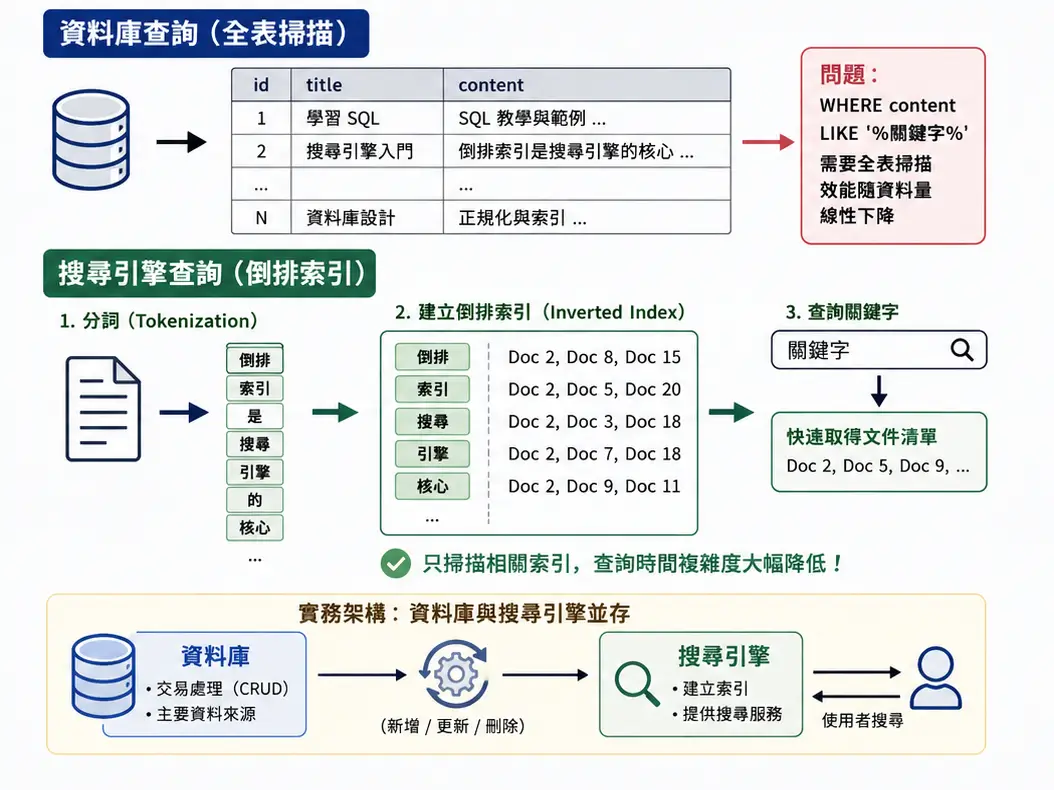
與直接從資料庫查詢不同,搜尋引擎會先將資料建立成索引(Index),以解決「巨量文字檢索」與「模糊查詢效能」。
資料庫在處理精準匹配(例如 WHERE user_id = 100)或範圍查詢時效率極高,但在面對非結構化文字的全文檢索(例如 WHERE content LIKE '%關鍵字%')時,通常需要進行全表掃描(Full Table Scan),導致查詢效能隨著資料量增加而呈線性下降。
搜尋引擎的核心在於倒排索引(Inverted Index)技術。傳統資料庫是以「文件/資料列」為核心記錄包含哪些詞彙;倒排索引則是相反,先將所有文字進行「分詞(Tokenization)」處理,記錄「每個詞彙出現在哪些文件之中」,從而將查詢時間複雜度降低。
資料庫和搜尋引擎通常會同時存在,資料庫作為資料來源,搜尋引擎則同步資料後提供搜尋服務。
| 項目 | 資料庫 | 搜尋引擎 |
|---|---|---|
| 主要用途 | 資料儲存與交易處理 | 資料搜尋與檢索 |
| 查詢方式 | SQL 查詢 | 關鍵字查詢 |
| 全文搜尋 | 能力有限 | 原生支援 |
| 模糊搜尋 | 成本較高 | 原生支援 |
| 排序機制 | 依欄位排序 | 依相關性排序 |
| 聚合分析 | 可實作但較複雜 | 原生支援 |
| 適用場景 | CRUD、交易系統 | 搜尋與推薦系統 |
搜尋引擎的優勢
全文檢索能力
搜尋引擎利用分詞器(Tokenizer)將文字內容建立倒排索引(Inverted Index),快速找出包含指定關鍵字的文件。
例如搜尋 docker network,即使關鍵字出現在文章中間,也能快速找到相關內容。
模糊搜尋
使用者輸入內容未必完全正確。
例如搜尋 Elasticsarch,實際想搜尋 Elasticsearch 搜尋引擎可透過模糊匹配(Fuzzy Search)找出最接近的結果,這種能力在電商與知識庫系統中特別重要。
搜尋效能提升
搜尋引擎透過索引結構進行查詢,當資料量從數萬筆成長到數百萬筆時,仍能維持相對穩定的搜尋速度,因此大型網站通常不會直接使用資料庫承擔所有搜尋需求。
關鍵字權重排序
搜尋結果不只是找到資料,更重要的是找到最相關的資料。
例如搜尋 docker,搜尋引擎可能依據條件計算相關性:
- 標題是否包含關鍵字
- 關鍵字出現次數
- 更新時間
- 點閱數
- 使用者行為
讓最符合需求、最相關的內容排在前面。
篩選與聚合分析
搜尋引擎除了搜尋,也能進行即時統計分析。
例如電商網站常見的篩選功能:
1 | 手機 |
這類統計結果通常稱為 Aggregation(聚合分析),搜尋與分析可以同時完成,而不需要額外執行複雜統計查詢。
適合導入搜尋引擎的場景
並非所有系統都需要搜尋引擎,若系統只有少量資料且以 CRUD 為主,資料庫通常已足夠,但是當查詢需求超越「精準比對」時,導入搜尋引擎能顯著提升系統的 I/O 與使用者體驗。
電商商品搜尋
電商平台的商品品項繁多,且使用者行為高度依賴關鍵字查詢,搜尋引擎能提供商品名稱、描述、規格的即時檢索,並同時計算出分類、品牌、價格區間的聚合統計,透過權重調整,營運團隊還能人為提高特定贊助商品或促銷商品的排序得分。
文章或文件搜尋
技術部落格、新聞網站或文件系統通常需要全文檢索。
例如搜尋 Kubernetes Ingress,搜尋引擎能直接從大量文章內容中找到相關段落,而不僅限於標題比對。
AI RAG 應用
在現代 LLM 應用中,為了避免模型產生幻覺(Hallucination)並提供即時資訊,通常會採用 RAG 架構。搜尋引擎在其中擔任「檢索器(Retriever)」的角色,透過傳統文本搜尋(Lexical Search)或結合向量空間的語義搜尋,快速篩選出最相關的資料提供給 LLM 參考。
實務範例
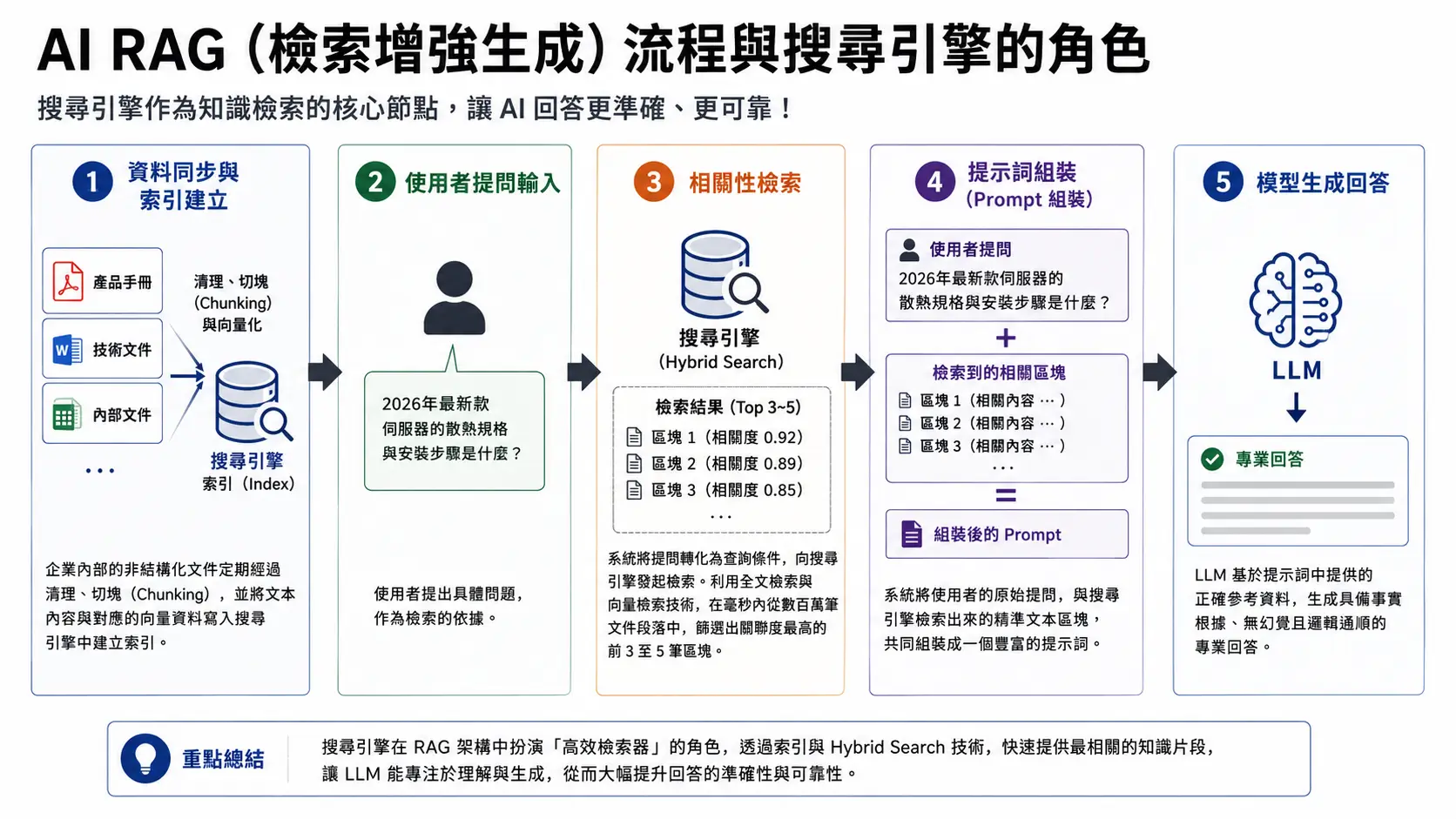
以 AI RAG(檢索增強生成) 系統為例,搜尋引擎在此架構中作為知識檢索的核心節點。
- 資料同步與索引建立:企業內部的非結構化文件(如產品手冊、技術文件)定期經過清理、切塊(Chunking),並將文本內容與對應的向量資料寫入搜尋引擎中建立索引。
- 使用者提問輸入:提出具體問題,例如:「2026年最新款伺服器的散熱規格與安裝步驟是什麼?」。
- 相關性檢索:系統將提問轉化為查詢條件,向搜尋引擎發起檢索。搜尋引擎利用全文檢索與向量檢索技術(Hybrid Search),在毫秒內從數百萬筆文件段落中,篩選出關聯度最高的前 3 至 5 筆區塊。
- 提示詞組裝:系統將使用者的原始提問,與搜尋引擎檢索出來的精準文本區塊,共同組裝成一個豐富的提示詞(Prompt)。
- 模型生成回答:LLM 基於提示詞中提供的正確參考資料,生成具備事實根據、無幻覺且邏輯通順的專業回答。
結論
搜尋引擎的核心價值在於建立高效率的資料檢索能力,提升全文搜尋、模糊匹配、相關性排序、大量資料查詢的效能,解決關聯式資料庫在非結構化資料的效能瓶頸,對於現代電商平台、內容網站、企業知識庫與 AI 應用而言,搜尋引擎已逐漸成為系統架構中的重要元件之一。


